How to Use Minimax to Create Natural LipSync Video

In today's global digital landscape, multilingual video content is no longer optional—it is a necessity. From YouTube channels targeting international audiences to corporate e-learning modules delivered across borders, creators are seeking ways to produce content that resonates with diverse viewers. Traditional dubbing and voice-over methods are expensive, time-consuming, and often lack the emotional nuance that audiences expect.
Enter Minimax AI, an AI-powered voice model that revolutionizes how creators produce multilingual content. With Minimax algorithm, users can generate voices that maintain tone consistency, clarity, and emotional authenticity, regardless of language. Integrating Minimax algorithm with lipsync.video allows creators to align perfectly AI-generated speech with character mouth movements, saving time while maintaining high-quality production.

The Growing Demand for Multilingual Video Content with Minimax
The global content landscape has changed dramatically. Audiences are no longer restricted to one platform, one language, or one region. Whether you are a YouTuber, a TikTok creator, an online educator, or a company producing customer training materials, your viewers now expect multilingual, accessible, and emotionally engaging video content.
This rapid shift created new pressure:
- Creators must publish more content, faster
- Brands must speak to global audiences
- Educators must teach in multiple languages
- Social media users want fun voice transformations and character dialogue videos
Traditionally, producing multilingual audio required hiring multiple voice actors, booking studios, paying translators, and spending long hours editing. This workflow was expensive, slow, and difficult to scale.
With Minimax AI, the problem seemed solved — but early generation models had serious limitations:
- Robotic voices
- Monotone delivery
- Wrong pacing
- Lip-sync mismatch
- Not enough emotional expression
- Poor multilingual accuracy
Creators needed something better、Something clearer、Something more natural、Something that could match lip movements accurately and create believable speech patterns.
Minimax algorithm technology ensures that every intonation and emphasis feels natural. For creators, this means a single workflow can now cater to multiple languages without hiring additional voice actors, dramatically reducing production costs and increasing scalability. Whether it's a tutorial, an advertisement, or a YouTube vlog, Minimax algorithm makes multilingual content creation more accessible and efficient.

Minimax’s Strengths: Clarity, Tone Control, and Emotional Delivery
1、Clearer Vocal Output Ideal for Ads and Educational Narration
Clarity is essential in categories like advertising and e-learning. Minimax algorithm delivers crisp articulation, reducing the risk of misheard words and improving audience comprehension. For e-learning companies teaching across multiple regions, this clarity is critical.
Ads also benefit: a clear voice helps brands communicate their message instantly, especially in short-form campaigns where every second counts.
2、Flexible Tone Styles for Storytelling and Branded Video Voices
Minimax algorithm gives creators granular control over tone—calm, energetic, warm, serious, or playful. This flexibility allows creators to match vocal style to content category. Storytellers can craft emotional arcs, educators can maintain a neutral instructional tone, and marketers can fine-tune their brand voice.
Maintaining a consistent tone across hundreds of videos is almost impossible with human actors, but Minimax AI makes it scalable.
3、Emotional Delivery That Makes Characters Sound More Real
A major weakness of many older models is their flat emotional quality. With Minimax algorithm, AI-generated voices can convey excitement, empathy, or urgency convincingly. For instance, e-learning creators can simulate an engaging teacher’s voice, while gaming streamers can animate character dialogues that resonate with viewers emotionally.
Additionally, Minimax algorithm integrates seamlessly with lipsync.video, enabling users to synchronize high-quality voices with visual content effortlessly. This combination maximizes viewer engagement and saves production time, making it an essential tool for modern content creators.
How to Use Minimax to Produce Natural LipSync Video
Step 1 — Upload Your Video to Begin the Minimax Workflow
Using Minimax algorithm inside lipsync.video begins with a simple first step: uploading your video. Creators can upload any portrait-style or talking-face video they want to enhance. Because Minimax algorithm produces clear and stable voice output, starting with a clean video file helps ensure the final talking video or singing video looks more natural.
Once the video is uploaded in lipsync.video, the system automatically prepares the face-tracking and timing structure that will later sync with your Minimax-powered audio.
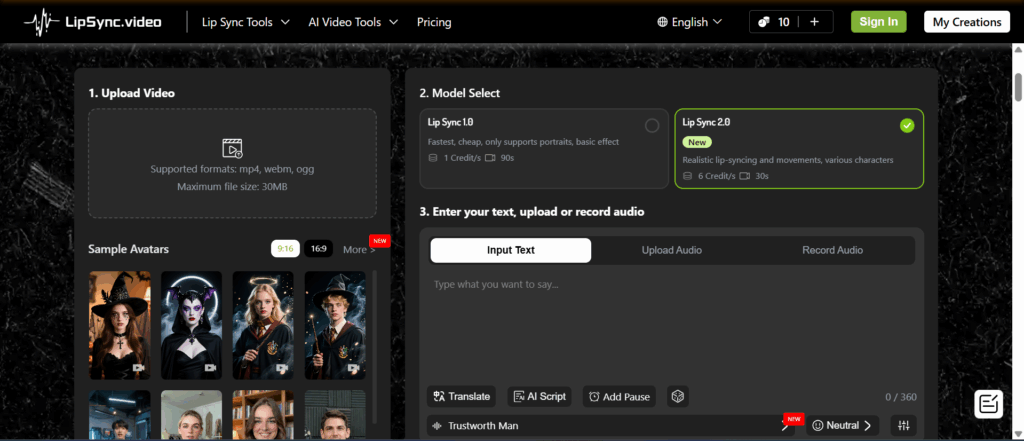
Step 2 — Select the Model: Basic or Advanced (Powered by Minimax)
After uploading your video, creators can select between 1.0 and 2.0 models. Both are optimized for high-quality lip-sync, but the Advanced mode offers smoother emotional transitions and more precise phoneme alignment—benefits that come directly from Minimax’s acoustic strengths.
Lipsync.video allows creators to match Minimax’s capabilities to their specific use cases, whether they need fast processing or highly expressive voice generation for ads, educational videos, or character storytelling.

Step 3 — Enter Text, Upload Audio, or Record Voice with Minimax Precision
The final step before generation is choosing how you want to supply your audio. lipsync.video supports three flexible options:
- Enter your text — The system uses Minimax AI algorithm to generate natural, multilingual AI speech.
- Upload audio — Perfect for creators who already have Minimax-generated voiceovers.
- Record audio directly — Ideal for quick drafts or personalized voice input.
Minimax AI algorithm ensures clarity, emotion, and accurate phoneme delivery, all of which directly improve the lip-sync video output. Once your audio source is selected, simply click to generate—and lipsync.video will merge your video with Minimax-powered speech to produce a realistic talking video or smooth singing video.
Minimax Stands Out Among AI Voice Models
1、High Stability and Low Latency
One of the main technical advantages of Minimax algorithm is its ability to deliver highly stable audio output with minimal latency. Whether creators are generating single-voice narrations or large batches of content, Minimax AI maintains consistent performance.Minimax Ai voices sound smooth, human, and consistent. This is a major reason Minimax AI performs exceptionally well in lip-sync workflows—fewer mismatches, fewer timing issues, and a more believable final video.
2、Natural Pacing and Phoneme Accuracy
Minimax algorithm is optimized for natural pacing, meaning the generated speech contains realistic timing, pauses, and emphasis. More importantly, it ensures that lip movements in videos align precisely with the audio. This is a major reason Minimax Ai performs exceptionally well in lip-sync workflows—fewer mismatches, fewer timing issues, and a more believable final video.
3、Minimal Artifacts Compared to Other Models
Unlike many traditional or older-generation AI voice models, Minimax algorithm produces fewer audio artifacts such as robotic tones, clipping, or awkward transitions. This makes the output suitable for commercial advertising, educational lectures, or branded content where professionalism is critical.

Benefits for Content Creators Using Minimax
1、Ad Creators: Consistent Brand Voice Without Hiring Voice Actors
Advertising teams often struggle with scheduling voice actors, maintaining consistent tone across campaigns, and keeping production costs low with Minimax AI that can be reused endlessly.Marketers can quickly test multiple tone styles, create multilingual versions of the same ad, and update scripts instantly—all without depending on external teams.
2、YouTube Creators: Faster Production With High-Emotion Voiceovers
YouTube creators depend heavily on speed and emotional engagement. Minimax algorithm allows them to generate expressive voiceovers that suit commentary videos, storytelling, ASMR, or educational breakdowns.
Because the model is fast, creators can maintain frequent posting schedules. And since Minimax AI supports emotional nuance, long-form content such as narratives, documentaries, or reactions becomes more compelling.
3、E-Learning Platforms: Clear Multilingual Narration for Global Learners
For e-learning platforms, Minimax algorithm helps scale courses to multiple regions by generating clear multilingual narration. The model’s consistent pacing and articulate pronunciation are valuable for instructional material where understanding is critical.
Additionally, Minimax AI integrates seamlessly with lipsync.video, enabling users to synchronize high-quality voices with visual content effortlessly. This combination maximizes viewer engagement and saves production time, making it an essential tool for modern content creators.

Conclusion
In summary, Minimax AI is transforming the way creators produce high-quality, multilingual, and emotionally rich audio for videos. By integrating Minimax algorithm into lipsync.video, creators can quickly turn scripts, recordings, or AI-generated voiceovers into polished talking videos and singing videos with precise lip-sync. Whether you are a marketer, educator, or YouTube creator, exploring Minimax-powered workflows can save time, enhance engagement, and elevate your content to a professional level. Try lipsync.video today and experience the next generation of AI voice and video creation.